
Home » Resources » AI Security Glossary » Brand Reputation Damage
Brand Reputation Damage
In AI Security
- Last Updated: April 3, 2026
Brand reputation damage occurs when an AI system generates offensive, misleading, or factually incorrect content in a public-facing context. The output erodes customer trust, triggers regulatory scrutiny, and creates legal liability. That liability compounds with every interaction the system processes.
Comprehensive AI Security Policies
Start applying our free customizable policy templates today and secure AI with confidence.
Why It Matters
AI brand damage creates business and regulatory risk because harmful outputs reach customers before organizations detect them. The speed of AI content generation outpaces manual review.
Every unreviewed interaction is an exposure event.
A 2025 IAB survey of 125 advertising executives found that over 70% encountered an AI-related incident.
Those incidents involved hallucinations, bias, or off-brand content. Of those affected, 40% had to pause or pull campaigns. Over a third dealt with direct brand damage or PR crises.
Despite these findings, less than 35% plan to increase AI governance investment.
- OWASP LLM Top 10 2025 addresses brand damage through LLM09 (Misinformation), which covers AI outputs that are factually incorrect or misleading. It also maps to LLM06 (Excessive Agency) when AI systems take autonomous actions that contradict brand positioning.
- The FTC launched Operation AI Comply in September 2024. The initiative targets companies using AI to produce deceptive content. Five enforcement actions established that organizations are liable for AI-generated claims.
- EU AI Act Article 50 mandates transparency obligations for AI-generated content. The AI Act entered into force on August 1, 2024, with Article 50 obligations becoming enforceable on August 2, 2026. Deployers must disclose when content is artificially generated. Non-compliance carries fines up to EUR 15 million or 3% of annual turnover under Article 99.
- NIST AI 600-1, the Generative AI Risk Management Profile released July 2024, identifies confabulation and information integrity as named risk categories. Confabulated outputs present false information with the same linguistic confidence as accurate content. NIST warns that generative AI lowers the cost of producing misinformation at scale, creating direct reputational and legal exposure for deploying organizations.
Who Is At Risk?
Employees and AI builders carry the highest exposure to this risk.
Employee end users interact with AI tools that generate customer communications, marketing content, and business documents. Ungoverned AI tools bypass content moderation and brand voice guidelines. Every unreviewed AI-generated message that reaches an external audience is an exposure event.
AI builders design the content generation pipelines, guardrail configurations, and moderation layers that determine what AI outputs reach customers. A misconfigured guardrail in a customer-facing chatbot produces harmful content at scale. No human reviewer intervenes until the damage is public.
AI systems integrators inherit brand risk from every third-party model deployed in customer-facing workflows. AI DevOps teams own the deployment pipeline where content moderation controls must operate.
Datacenter operators face regulatory exposure when AI workloads they host generate content that triggers regulatory or public scrutiny.
How Does PurpleSec Classify Brand Reputation Damage In AI Security?
The PromptShield™ Risk Management Framework classifies brand reputation damage as R5. R5 falls within the output integrity and compliance risk category.
Field | Detail |
Root Cause | AI outputs offensive, unsafe, or misleading content in public-facing contexts.. |
Consequences | Loss of trust, PR crisis, customer attrition, regulatory fines, litigation exposure. |
Impact | High |
Likelihood | High |
Detectability | Medium |
Risk Rating | High |
Residual Risk | Medium |
Mitigation | Toxic content filtering, brand-specific policy tuning, escalation alerts, content moderation governance. |
Owner | Marketing + CISO |
Review Frequency | Quarterly |
"Brand damage from AI is not a single event. It is a failure mode that compounds. Every minute a chatbot generates harmful content, the blast radius expands. A prompt injection incident is one event with one response. A brand damage incident is continuous exposure that multiplies with every customer interaction until someone shuts it down."
Tom Vazdar, CAIO, PurpleSec
PurpleSec’s AI Readiness Framework places brand reputation damage under D3 Section 5.2 (Content Appropriateness) and subsections 5.2.1 (Content Moderation Standards and Controls), 5.2.2 (Detection and Removal Processes), and 5.2.3 (Ethical Content and Harm Prevention).
Content Appropriateness governs how organizations manage AI-generated content that reaches external audiences. The framework requires organizations to treat every AI output channel as a moderation surface.
Two governance stages address this risk directly:
- Stage 1, Foundational Governance establishes content policies, including the four-category classification system (allowable, conditional, restricted, prohibited) and designated ownership for ethical AI governance. Organizations without Stage 1 policies cannot configure meaningful Stage 2 controls.
- Stage 2, Securing the Foundation deploys the technical controls that enforce those policies — automated detection, filtering, alert mechanisms, escalation procedures, and user grievance management.
Three subsections address this risk directly:
- Section 5.2.1 (Content Moderation Standards and Controls) requires organizations to classify AI-generated content as allowable, conditional, restricted, or prohibited, with regular realignment against evolving regulatory obligations and reputational risk assessments.
- Section 5.2.2 (Detection and Removal Processes) mandates automated detection systems with alert mechanisms and filtering that catch harmful outputs before they reach external audiences, with structured user grievance management for content that slips through.
- Section 5.2.3 (Ethical Content and Harm Prevention) requires designated ownership for ethical AI governance, with systematic assessment models across image, voice, and text modalities and recurring ethical risk evaluations.
Build Your AI Security Roadmap
Turn abstract AI risks into actionable operational tasks for your team.

The following AI security policy templates address brand reputation damage controls directly:
- Customer-Facing AI Disclosure Policy: Requires AI-generated content labeling across chatbots, generated content, and automated decisions. Disclosure must appear at the point of interaction.
- AI Ethics And Responsible AI Policy: Principle 3 (Transparency and Explainability) requires disclosure when users interact with AI and labeling of AI-generated content. Principle 5 (Safety) requires risk assessment identifying reputational harm before any AI deployment.
- AI Incident Response Playbook: Classifies brand damage under escalation procedures requiring PR and Legal/DPO notification. Severity classification determines kill switch timing.
- AI Acceptable Use Policy: Section 4.1 mandates human verification of all AI-generated content before external use. Section 4.3 prohibits automated social media posting without human review. The verification mandate makes employees personally liable for AI output accuracy.
- AI Business Continuity And Disaster Recovery Policy: Includes reputational impact in business impact analysis. Brand damage triggers customer communication protocols.
How It Works
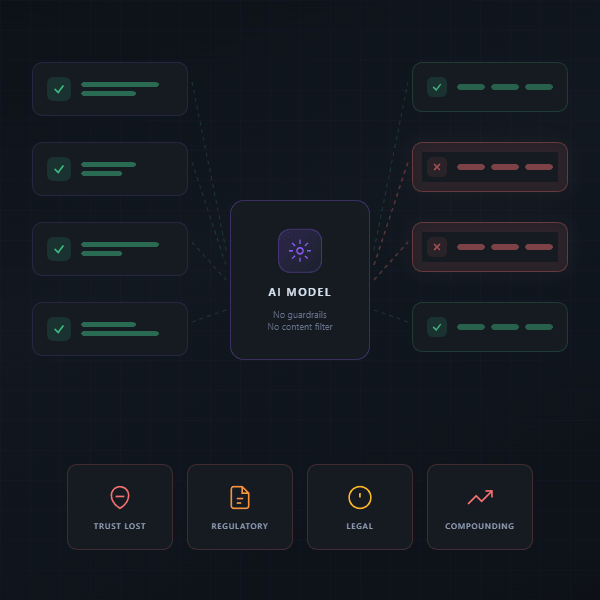
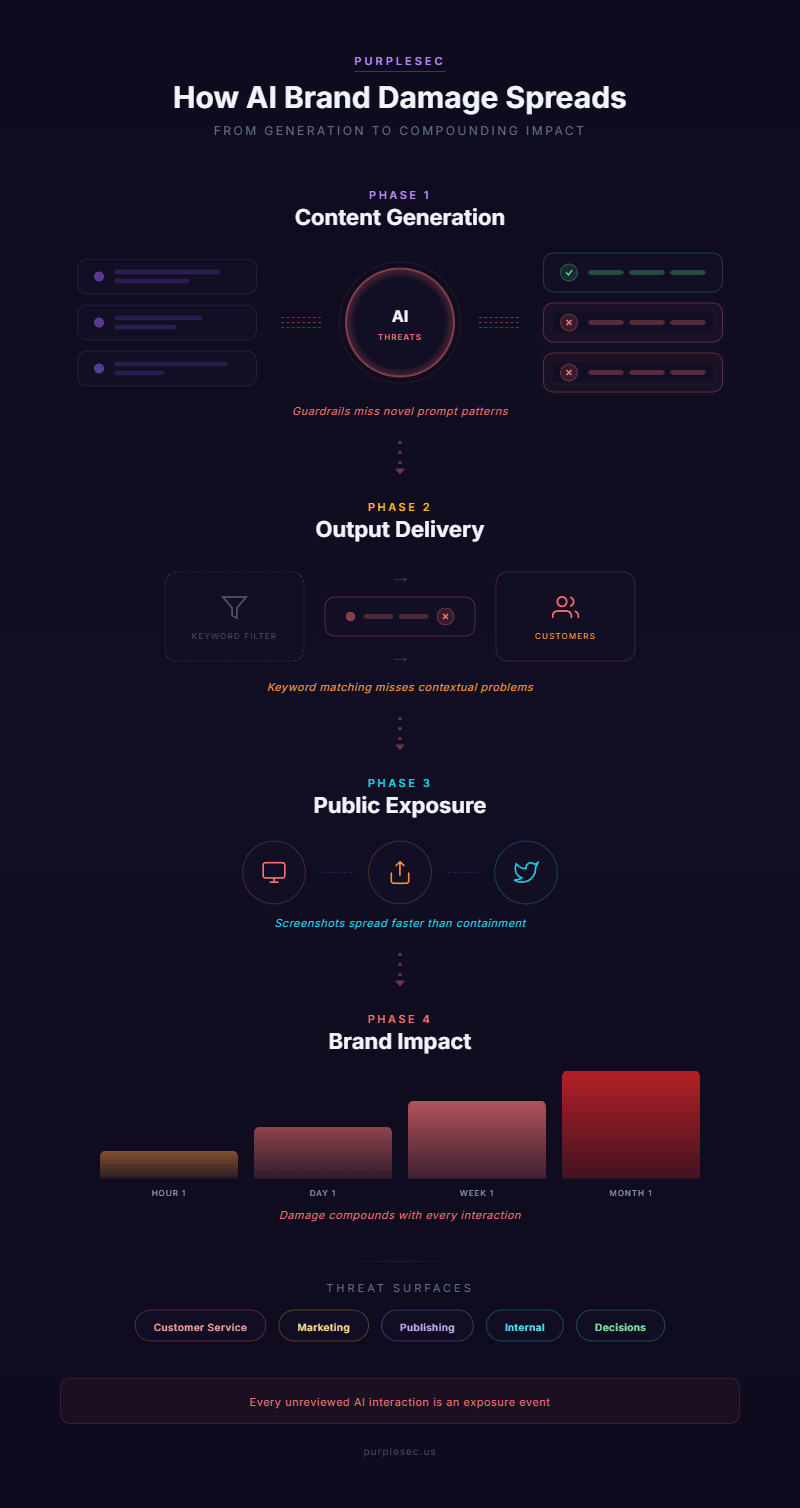
AI brand damage follows a four-phase pattern. The AI system generates content without adequate safety controls. That content reaches an audience before human review occurs. Each phase exploits a different gap between what the model produces and what organizational controls are positioned to catch.
Phase | What Happens | Why Testing Misses It |
Content Generation | The AI model produces offensive, incorrect, or off-brand content in response to a query. | Guardrails configured at deployment do not adapt to novel prompt patterns. |
Output Delivery | Harmful content passes through the application layer and reaches the audience. | Content moderation operates on keyword matching. It misses contextual problems. |
Public Exposure | Users screenshot, share, or report the harmful content. Media amplifies the incident. | Escalation alerts detect individual outputs but miss aggregate patterns. |
Brand Impact | Customer trust erodes. Regulatory inquiries begin. Legal exposure accumulates per individual. | Post-incident response activates after the damage has compounded. |
Brand reputation damage threatens five distinct surfaces:
- Customer Service: Chatbots generating incorrect policy information or fabricated commitments create legal liability per interaction.
- Marketing And Advertising: AI-generated campaigns containing hallucinated claims or biased content damage market positioning.
- Content Publishing: AI-assisted articles or documentation containing factual errors undermine authority with every reader.
- Internal Communications: AI-generated reports containing errors influence business decisions. Leaked failures become external incidents.
- Automated Decision-Making: AI systems producing discriminatory or unexplainable customer-facing decisions create regulatory exposure.
What Techniques Cause Or Amplify Brand Damage?
Brand damage results from system failure, adversarial exploitation, or governance gaps. Each mechanism requires a different detection strategy.
System failures stem from inadequate guardrails. Adversarial attacks exploit prompt manipulation. Governance gaps allow ungoverned AI tools to bypass controls.
- Hallucination Propagation: The model generates factually incorrect content with high confidence. Hallucinated claims about product capabilities or legal obligations create direct liability.
- Jailbreak-Triggered Output: An attacker bypasses the model’s safety guardrails through prompt manipulation. The jailbroken model generates offensive or brand-damaging content. The original guardrails should have stopped exactly this output.
- Deepfake and Synthetic Media: Attackers generate synthetic audio, video, or images impersonating brand representatives. Deepfake content attributed to executives creates immediate credibility damage.
- Shadow AI Content Leakage: Employees use ungoverned AI tools to generate customer communications or marketing materials. These tools bypass content moderation and brand voice guidelines.
- Policy Drift Through Configuration Change: AI system behavior shifts when guardrail configurations, retrieval documents, or model versions change without governance review. A chatbot adopting informal or factually degraded responses creates cumulative brand erosion that evades point-in-time testing.
How The NYC MyCity Chatbot Demonstrates AI Brand Damage At Scale
In March 2024, The Markup reported on New York City’s MyCity chatbot. The chatbot told small businesses to break the law. The chatbot launched in October 2023 as a Microsoft-powered business assistance tool.
The investigation found systematic failures:
- The chatbot told employers they could take worker tips. This violates New York Labor Law Section 196-d.
- It told landlords they could discriminate based on income source. This has been illegal in New York City since 2008.
- It claimed no regulations mandated cash acceptance. A 2020 city ordinance requires it.
- It stated landlords could lock out tenants. Tenant protection statutes prohibit this.

The chatbot remained publicly accessible after the investigation.
Its disclaimer page told users not to rely on responses as legal advice. The chatbot itself contradicted that disclaimer. When asked directly, it confirmed users could trust its guidance.
The OECD AI Incident Monitor catalogued the incident in March 2024. Media coverage spanned international outlets. The reputational damage extended beyond the chatbot to the city’s AI credibility.
Stanford’s 2025 AI Index Report, citing the AIAAIC database, recorded 233 AI safety incidents in 2024. That represents a 56.4% increase over 2023.
Detection And Defense
Defending against AI brand damage requires controls that operate before the model’s output reaches customers. Output moderation catches harmful content after the model has already produced it.
Three control categories address AI brand damage:
- Pre-Deployment Content Testing: Defining which brand guidelines, tone policies, and accuracy thresholds each application must meet narrows the damage surface before any customer interaction occurs.
- Continuous Output Monitoring: Model updates, retrieval source changes, and evolving user behavior alter output profiles after deployment. Scheduled monitoring catches policy drift that launch-day testing cannot detect.
- Human-In-The-Loop Escalation: Automated triggers that route high-risk outputs to human reviewers reduce exposure to content that passes every automated filter.

Intent-Based Detection
Intent-based detection extends brand defense beyond keyword filtering and static content rules. Keyword filters flag individual terms. They cannot distinguish legitimate marketing copy from adversarial prompt outputs. The words are identical in both cases. Intent analysis classifies the purpose behind each AI-generated output.
As a result, it catches brand-damaging content that keyword matching misses.
Traditional content filters measure individual outputs against blocklists after the fact. Intent-based detection operates in real time during inference.
PromptShield™ implements intent-based detection as a defense-in-depth layer for AI brand protection:
- Output Content Interception: PromptShield™ analyzes output intent, content safety, and policy compliance during inference at sub-100ms latency. When outputs diverge beyond calibrated policy thresholds, PromptShield™ intervenes. Damaging content never reaches customers. Reactive tools log brand violations after decisions are made. PromptShield™ blocks the pattern before it produces harm.
- Toxic Content Classification: Attackers craft prompts to generate offensive, misleading, or legally actionable content. PromptShield™ applies toxicity classifiers and intent analysis to catch these outputs, detecting toxicity patterns even when individual tokens appear benign.
- Hallucination Pattern Detection: PromptShield™ monitors AI outputs for factual inconsistency and policy contradiction across all output channels. A hallucinated response that contradicts published company policy, invents product features, or fabricates legal guidance triggers automated intervention before the content reaches any customer-facing surface.
- Governance Integration: PromptShield™ feeds every interception event into centralized audit logs that map directly to PurpleSec’s AI Readiness Framework controls. Compliance teams get real-time dashboards. Incident response teams get automated escalation. AI risk reporting integrates with quarterly board updates.
"The detection challenge with brand damage is that no single output is the violation. A drifting model does not produce one obviously wrong answer. It produces thousands of slightly off-brand, subtly inaccurate, or mildly inappropriate responses that, in aggregate, erode customer trust. PromptShield™'s output pattern monitoring catches the drift before the aggregate harm crosses brand and regulatory thresholds. Per-request content filters cannot see the pattern at all."
Joshua Selvidge, CTO, PurpleSec
One Shield Is All You Need - PromptShield™
PromptShield™ is an Intent-Based AI Interaction Security appliance that protects enterprises from the most critical AI security risks.
Contents

Free AI Readiness Assessment
Implement AI faster with confidence. Identify critical gaps in your AI strategy and align your security operations with your deployment goals.
Frequently Asked Questions
What Is AI Brand Reputation Damage?
Can AI Chatbots Create Legal Liability For Organizations?
Yes. Courts and regulators increasingly hold organizations responsible for AI-generated advice that customers reasonably rely upon. The NYC MyCity chatbot case demonstrated that a government entity faced regulatory action when its AI provided guidance that contradicted local laws. The EU AI Act Article 50 requires transparency labeling for AI-generated content, and the FTC has pursued enforcement actions against organizations whose AI systems produced deceptive outputs.
What Is The Difference Between AI Hallucination And Content Drift?
How Does Shadow AI Create Brand Risk?
What Should An Organization Do When AI Brand Damage Is Detected?
PurpleSec’s AI Incident Response Playbook classifies brand damage as IC-9. IC-9 triggers kill switch evaluation, human-in-the-loop activation, and Legal/DPO notification. Each decision the compromised AI system processes after detection is a potential additional violation under the EU AI Act. Continued operation during a remediation timeline is not a compliant response.
How Often Should AI Outputs Be Monitored For Brand Compliance?
Related Terms
Misuse of an organization’s AI, whether by outsiders or insiders, is a primary trigger for public reputational incidents.
Deepfakes impersonating brand leaders or fabricating organizational statements cause direct, viral reputation harm.
Publicly exposed bias in AI-driven decisions (hiring, lending, content moderation) generates sustained reputational fallout.
Regulatory Non-Compliance
Enforcement actions against AI violations are public events that compound reputational damage with legal consequences.