
AI Security Testing
AI security testing targets meaning, intent, and model behavior where the payload is natural language. The job is to close the gap between instruction and behavior before an attacker does. Most AI systems ship without anyone verifying they refuse the attacks that will reach them. AI security testing closes that gap.
- Last Updated: April 21, 2026
AI Security Testing Terms & Definitions
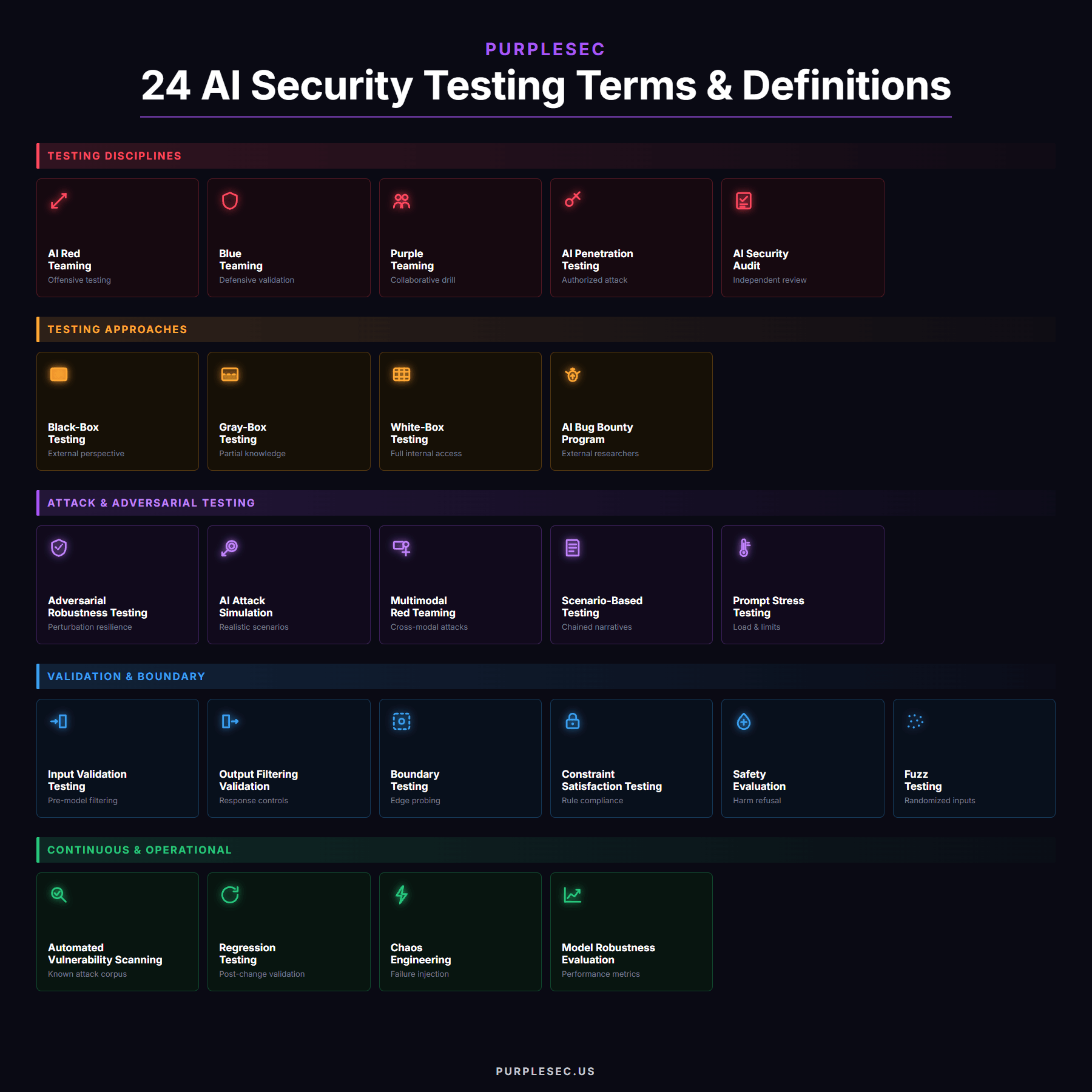
This page defines 25 methods, frameworks, and practices used to find AI vulnerabilities before attackers do. That covers adversarial robustness testing, STRIDE-AI threat modeling, and the full red, blue, and purple team progression. Every term maps to our AI Readiness Framework and the PromptShield™ Risk Management Framework so each test ties back to a measurable control.
Adversarial Robustness Testing
Testing an AI model against inputs deliberately crafted to degrade, mislead, or manipulate its behavior, measuring resilience against perturbations, evasion attempts, and edge cases.
AI Attack Simulation
Running realistic attack scenarios against a deployed AI system to measure how controls hold against prompt injection, jailbreaking, data extraction, and autonomous-action abuse.
AI Bug Bounty Program
A structured program that pays external researchers for discovering and responsibly disclosing vulnerabilities in an organization’s AI systems, extending coverage beyond internal testing capacity.
AI Penetration Testing
The authorized simulation of attacks against an AI system’s full stack, covering model behavior, APIs, plugins, and supporting infrastructure to identify exploitable weaknesses before adversaries do.
AI Red Teaming
The offensive testing discipline that probes AI systems for cognitive exploits like prompt injection, jailbreaking, bias elicitation, and alignment failure using frameworks like STRIDE-AI and the OWASP LLM Top 10.
AI Security Audit
The independent review of an AI system’s security posture against regulatory requirements, framework obligations, and internal policies, producing a documented evidence trail for compliance.
Automated Vulnerability Scanning
Running tools like Garak, PyRIT, and NeMo Guardrails to execute thousands of known attack prompts and establish a baseline Attack Success Rate before manual testing begins.
Black-Box Testing
Testing an AI system without internal access to model weights, system prompts, or architecture, simulating the perspective of an external attacker with only public-facing access.
Blue Teaming
The defensive testing discipline that validates detection, containment, and response capabilities against simulated attacks, measuring mean time to detect and mean time to contain.
Boundary Testing
Probing the edges of an AI system’s safety constraints, content policies, and tool permissions to identify where rules enforce rigidly and where they bend under pressure.
Chaos Engineering
Deliberately injecting failures, latency, and degraded dependencies into AI systems in production to validate resilience, failover behavior, and graceful degradation.
Constraint Satisfaction Testing
Testing whether an AI system consistently obeys explicit constraints (format rules, content policies, output schemas) across diverse inputs and conversational contexts.
Fuzz Testing
Feeding randomized, malformed, or extreme inputs into AI endpoints to uncover crashes, unexpected behaviors, parameter validation gaps, and resource exhaustion vulnerabilities.
Gray-Box Testing
Testing an AI system with partial internal knowledge such as system prompts, tool lists, or architectural diagrams, combining external attack perspective with informed targeting.
Input Validation Testing
Verifying that the AI system correctly rejects malformed, oversized, or policy-violating inputs before they reach the model, including payload splitting and encoding bypasses.
Model Robustness Evaluation
The quantitative assessment of how well a model maintains performance and safety under adversarial conditions, drift, and distribution shifts, with metrics documented in the model card.
Multimodal Red Teaming
Testing AI systems that accept images, audio, video, or documents for cross-modal injection attacks where payloads hidden in one modality manipulate behavior across others.
Output Filtering Validation
Testing whether output controls reliably detect and block PII leakage, toxicity, system prompt extraction, and hallucinated information before responses reach users or downstream systems.
Prompt Stress Testing
Running high volume, maximum-length, or computationally expensive prompts against an AI system to validate rate limits, cost controls, and denial-of-wallet defenses.
Purple Teaming
The collaborative exercise where red and blue teams work together, with the red team running attacks while the blue team validates that detection and response actually fire as designed.
Regression Testing
Re-running the established attack corpus after every model update, prompt change, or guardrail modification to confirm no previously blocked attack now succeeds.
Safety Evaluation
The structured assessment of whether an AI system refuses harmful, illegal, or policy-violating requests across categories like CBRN, violence, self-harm, and CSAM.
Scenario-Based Testing
Running end-to-end attack narratives that chain multiple techniques across sessions, simulating how sophisticated adversaries combine reconnaissance, exploitation, and exfiltration in a real engagement.
White-Box Testing
Testing an AI system with full internal access to model weights, training data, system prompts, and tool configurations, enabling targeted probes of known weaknesses and architectural assumptions.

A Practical Framework For Secure, Responsible AI
AI security is not a one-time deployment. It is an ongoing discipline. PurpleSec emphasizes structured discovery, contextual risk analysis, practical control implementation, and continuous refinement.
Frequently Asked Questions
How Is AI Security Testing Different From Traditional Penetration Testing?
Traditional penetration testing targets code, networks, and infrastructure. Buffer overflows, SQL injection, misconfigurations. AI security testing targets meaning, intent, and model behavior. The vulnerability is the model’s helpful nature. The exploit is natural language. The payload is an instruction rather than shellcode. That is why the industry adapted STRIDE into STRIDE-AI, adding two categories that do not exist in conventional threat models: Alignment Failure and Injection. A tester who only runs Burp Suite against an LLM endpoint will miss the attacks that actually matter.
How Does AI Security Testing Map To The OWASP LLM Top 10 And NIST AI RMF?
A complete testing program covers all ten OWASP LLM Top 10 categories with specific attack scenarios. That means LLM01 prompt injection (direct and indirect), LLM02 insecure output handling, LLM03 training data poisoning, LLM04 denial of service and denial of wallet, LLM05 supply chain, LLM06 sensitive information disclosure, LLM07 insecure plugins, and so on.
The NIST AI RMF governs how you scope, document, and escalate those findings, but it deliberately stops short of naming attacks. Treat OWASP as the offensive taxonomy. Treat NIST AI RMF as the governance wrapper around it. The coverage target is 80% of OWASP categories tested, with justified exceptions documented for the rest.
How Do These Testing Methods Work Together In A Real Engagement?
A mature engagement chains methods in sequence, each catching what the prior missed. It starts with a STRIDE-AI threat model to expose missing controls per attack class. Then an automated baseline using Garak or PyRIT runs 1,000+ known prompts to produce a measurable Attack Success Rate.
Multi-turn adversarial testing with PyRIT or custom scripts catches role-play escalation and payload splitting that single-turn scanners cannot reproduce. Expert manual testing using Burp Suite and curated attack corpora targets the system-specific attack surface.
A purple team loop validates whether the SIEM actually caught what the red team found. Skip any stage and total coverage drops into single digits. Single-stage programs ship vulnerable systems.
Do All Of These Testing Methods Apply To Every Organization?
Scope depends on how the AI is deployed, not on a generic checklist. Organizations running off-the-shelf AI tools prioritize input validation testing, scenario-based testing, and insider misuse simulations.
Organizations training custom models must add adversarial training data testing, membership inference, and model inversion to catch privacy leakage.
Organizations shipping customer-facing AI face prompt injection, jailbreaking, and regulatory exposure, which requires black-box, gray-box, and white-box testing combined with continuous red teaming. Map each system to the methods on this page based on its architecture, data access, and deployment context.
Which AI Security Tests Should Our Organization Run First?
Sort AI security tests into three tiers.
- Tier 1, run now: prompt injection testing and system-prompt extraction (LLM01 and LLM06). Prompt injection has been OWASP’s top LLM risk two years running. Information disclosure is the highest-impact finding when it succeeds.
- Tier 2, run next quarter: denial of wallet and supply chain validation (LLM04 and LLM05). Quick to execute, high business impact if controls fail.
- Tier 3, emerging watch list: alignment failure, insecure plugin design, and multimodal red teaming.
PurpleSec’s AI Readiness Framework maps each tier to concrete testing milestones based on your AI maturity.
What AI Security Testing Gaps Do Most Companies Overlook?
Most teams test direct prompt injection, see it blocked, and stop. The attacks that cause incidents are elsewhere. Indirect prompt injection hides inside retrieved documents, emails, or RAG sources. Multi-turn adversarial prompt chaining splits a malicious objective across harmless-looking messages.
Membership inference extracts training data from model outputs. Supply chain compromise arrives through unsigned model weights and pickle deserialization. Alignment failure quietly shifts an agent’s goal across a long conversation.
How Do We Measure Whether AI Security Testing Is Working?
Four metrics govern whether a system is production-ready.
- Attack Success Rate (ASR) under 1% proves guardrails hold under sophisticated attack
Mean Time to Detect (MTTD) under 15 minutes proves monitoring catches attacks before damage propagates
False positive rate under 2% proves legitimate traffic is not being blocked into uselessness
Zero P1/P2 critical findings proves no unremediated high-severity vulnerabilities remain
Realistic starting points look worse. New deployments often baseline at ASR 8-10% and MTTD over an hour. The discipline that matters is month-over-month trending on all four numbers.
Related Glossary Categories
The 21 attack vectors and failure modes spanning prompt injection, data exfiltration, bias, and supply chain compromise, each tied to measurable business impact.
The policies, roles, and accountability structures that determine who controls an AI system’s behavior, deployment decisions, and escalation paths.
Meeting regulatory obligations like the EU AI Act, NIST AI RMF, GDPR, and ISO 42001 before enforcement gaps become audit findings.
Identifying, assessing, and prioritizing AI-specific threats to apply controls proportional to actual business impact.
Ensuring AI systems operate fairly and transparently by closing the gap between what a model can do and what it should.
Protecting personal data throughout the AI lifecycle, from training collection through inference outputs, to prevent unintended exposure.
Securing the third-party models, datasets, and libraries an AI system depends on to prevent hidden backdoors in production.
Catching attacks and silent model failures at the inference layer, where natural-language payloads and behavioral drift escape signature-based tools.
The structured process for containing, investigating, and recovering from AI security events when preventive controls fail.