
AI Ethics In Cybersecurity
AI ethics in cybersecurity treats fairness, accountability, transparency, and alignment as engineering requirements with measurable controls. Closing that gap requires controls that operate at the decision layer, where fairness and alignment are tested against thresholds, not at the policy layer where principles are declared.
- Last Updated: April 21, 2026
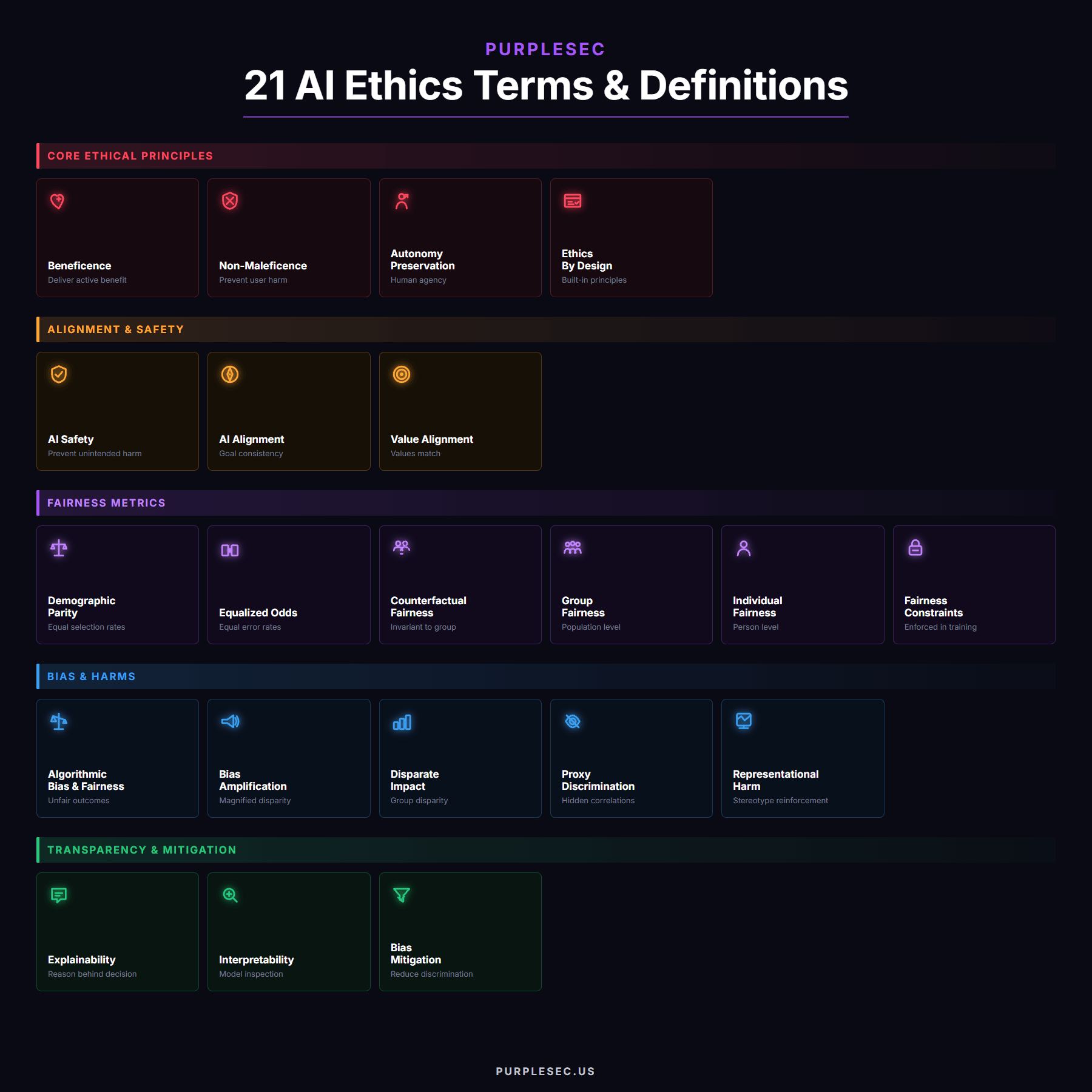
AI Ethics Terms & Definitions
This page defines 21 principles, metrics, and methods that govern whether an AI system behaves the way it should, and whether you can prove it. Each risk is mapped to our AI Readiness Framework and the PromptShield™ Risk Management Framework so ethical principles connect to a specific control, not a slogan.
AI Alignment
The engineering discipline of ensuring an AI system pursues the goals, values, and behavioral boundaries its operators intended rather than optimizing for proxy objectives that diverge under pressure.
AI Safety
The combined research and engineering effort to prevent AI systems from causing unintended harm through misuse, misalignment, emergent behavior, or deployment in contexts they were not designed for.
Systematic errors in AI outputs that produce unfair outcomes for specific groups due to skewed training data or flawed model design, measured against defined fairness thresholds.
Autonomy Preservation
The principle that AI systems should support human agency and informed decision-making rather than manipulating, nudging, or replacing user choice without consent.
Beneficence
The principle that AI systems must actively serve legitimate organizational and societal purposes rather than merely avoiding harm, justifying deployment through demonstrable benefit.
Bias Amplification
The effect where AI systems magnify existing demographic disparities in their training data, producing outputs more skewed than the baseline human decisions they learned from.
Bias Mitigation
The structured set of techniques (dataset augmentation, adversarial debiasing, post-processing modifications, fairness constraints) applied to reduce discriminatory outcomes across protected groups.
Counterfactual Fairness
A fairness definition requiring that an AI decision would remain the same if the individual had belonged to a different demographic group, with all other factors held constant.
Demographic Parity
A fairness metric requiring equal selection rates across demographic groups, with the EEOC four-fifths rule (0.80 ratio minimum) as the common compliance threshold.
Disparate Impact
A legal and statistical concept identifying when a neutral-looking AI decision rule produces systematically different outcomes for protected groups, triggering regulatory and civil rights exposure.
Equalized Odds
A fairness metric requiring equal true-positive and false-positive rates across demographic groups, ensuring the model performs equivalently for each protected class.
Ethics By Design
The practice of embedding ethical principles into AI system architecture, data pipelines, and development processes from the start rather than retrofitting them after deployment.
Explainability
The capability of an AI system to produce meaningful, audience-appropriate accounts of why it made a specific decision, using methods like SHAP, LIME, and counterfactual explanations.
Fairness Constraints
Mathematical conditions enforced during training or post-processing that require the model to satisfy a chosen fairness metric, such as demographic parity or equalized odds.
Group Fairness
Fairness measured at the population level, requiring statistical parity across demographic groups rather than evaluating each individual decision in isolation.
Individual Fairness
Fairness measured at the person level, requiring that similar individuals receive similar AI decisions regardless of their group membership.
Interpretability
The property of an AI system whose internal reasoning can be inspected and understood by humans, ranging from fully interpretable (decision trees) to opaque (deep neural networks requiring post-hoc methods).
Non-Maleficence
The principle that AI systems must not cause harm to users, third parties, or society, operationalized through prohibited-use policies and hard deployment gates for high-risk applications.
Proxy Discrimination
The persistence of discriminatory outcomes after protected characteristics are removed, because variables like zip code, school name, or employment gap still carry the same demographic signal.
Representational Harm
The harm caused when AI systems reinforce stereotypes, erase identities, or produce degrading depictions of specific groups, distinct from the allocative harm of denied resources.
Value Alignment
The broader challenge of ensuring an AI system’s objectives match human values across edge cases, cultural contexts, and long-horizon decisions where simple specifications fail.

A Practical Framework For Secure, Responsible AI
AI security is not a one-time deployment. It is an ongoing discipline. PurpleSec emphasizes structured discovery, contextual risk analysis, practical control implementation, and continuous refinement.
Frequently Asked Questions
How Is AI Ethics In Cybersecurity Different From AI Ethics In General?
General AI ethics frames the subject as values, norms, and societal impact. AI ethics in cybersecurity treats the same subject as a control surface.
Bias becomes measurable legal exposure. Explainability becomes audit evidence. Value alignment becomes an attack surface where adversarial prompts exploit gaps between intent and behavior. Fairness metrics become deployment gates. The shift in framing matters because it changes who owns the problem.
When ethics sits only with legal or HR, violations surface months after decisions ship. When ethics sits inside the security stack, violations are caught at the same layer as prompt injection and data leakage.
How Do These Ethics Principles Map To The EU AI Act, NIST AI RMF, And ISO 42001?
The three frameworks cover overlapping territory with different operational weight.
- EU AI Act Articles 9, 10, 13, and 14 require risk management, data governance, transparency, and human oversight for high-risk systems, with fines up to EUR 15 million or 3% of worldwide annual turnover under Article 10.
- The NIST AI RMF organizes controls across four functions (Govern, Map, Measure, Manage) and includes MEASURE 2.11 specifically for fairness and bias evaluation.
- ISO 42001 is the management-system standard that formalizes how those controls run day to day.
Treat the EU AI Act as the enforcement layer, NIST AI RMF as the taxonomy, and ISO 42001 as the operating system.
How Do Ethics Failures Turn Into Security Incidents?
Every category on this page produces a downstream security, compliance, or brand event when it breaks. A biased hiring model processing 200 applications a day generates 200 potential discrimination claims a day.
An opaque credit model fails an EU AI Act transparency audit and loses market access. An agent with weak value alignment gets manipulated by an adversarial prompt into taking autonomous action the operator never approved.
A fairness drift goes undetected for a quarter and the class action arrives with six months of decisions as exhibits. Ethics is a compounding risk category, which is why it sits inside the incident response playbook as a P1/P2 severity class.
What Ethics Gaps Do Most Companies Overlook?
Most programs focus on pre-deployment bias testing and stop there. The gaps that drive incidents are elsewhere. Proxy discrimination persists after protected characteristics are removed because zip code, school name, and employment gap carry the same signal.
Automation bias emerges when human reviewers override AI recommendations less than 1% of the time, which indicates rubber-stamp oversight rather than meaningful review.
Fairness metric gaming happens when teams optimize for demographic parity while violating equalized odds. Explainability ships only in technical logs where the users and regulators who need it cannot reach it. Alignment failure shows up in multi-turn conversations that quietly shift an agent’s goal away from the one it was deployed with.
Do All 21 Ethics Terms Apply To Every Organization?
Scope depends on use case, not on a generic list. The EU AI Act Annex III and PurpleSec’s AI Ethics Policy identify seven high-risk categories that trigger the full set:
- Employment
- Credit and financial services
- Healthcare
- Law enforcement
- Education
- Critical infrastructure
- Generative or foundation models.
Organizations operating in these domains must implement bias identification, fairness constraints, explainability, HITL oversight, and continuous monitoring across every affected system.
Organizations running lower-risk AI still owe transparency and non-maleficence, but the engineering burden is lighter. Map each AI system to its risk tier first, then apply the terms that match.
Which AI Ethics Controls Should We Prioritize First?
Sort AI ethics controls into three tiers.
- Tier 1, run now: pre-deployment bias testing using the EEOC four-fifths rule as a hard gate, plus HITL oversight for any decision affecting employment, credit, healthcare, or essential services. These controls stop the highest-impact violations at the source.
- Tier 2, run next quarter: explainability implementation using SHAP for global feature importance, LIME for individual decisions, and counterfactual explanations for user-facing interfaces. Explanations must surface in the UI, not only in technical logs.
- Tier 3, emerging watch list: continuous fairness monitoring for drift, alignment testing for agent systems, and representational harm evaluation for generative models.
PurpleSec’s AI Readiness Framework maps each tier to concrete milestones by AI maturity.
How Do We Measure Whether AI Ethics Controls Are Working?
Five metrics govern whether an AI ethics program is operational.
- EEOC four-fifths ratio at or above 0.80 for every protected group. Anything below blocks deployment.
- HITL override rate between 5% and 15%. Under 1% signals rubber-stamp review. Over 20% signals the AI is not ready for the decision.
- Explainability coverage at 100% for high-risk models with WCAG 2.1 AA compliance on explanation interfaces.
- Ethical review SLA under 15 business days for all mandatory reviews, with documented dissenting views.
- Zero unauthorized autonomous actions across all agentic deployments, measured at the interaction layer.
Trending these five numbers month over month is what separates an ethics program from an ethics statement.
Related Glossary Categories
The 21 attack vectors and failure modes spanning prompt injection, data exfiltration, bias, and supply chain compromise, each tied to measurable business impact.
The policies, roles, and accountability structures that determine who controls an AI system’s behavior, deployment decisions, and escalation paths.
Meeting regulatory obligations like the EU AI Act, NIST AI RMF, GDPR, and ISO 42001 before enforcement gaps become audit findings.
Identifying, assessing, and prioritizing AI-specific threats to apply controls proportional to actual business impact.
Validating an AI system’s resilience against prompt injection, jailbreaking, data poisoning, and model manipulation before attackers do.
Protecting personal data throughout the AI lifecycle, from training collection through inference outputs, to prevent unintended exposure.
Securing the third-party models, datasets, and libraries an AI system depends on to prevent hidden backdoors in production.
Catching attacks and silent model failures at the inference layer, where natural-language payloads and behavioral drift escape signature-based tools.
The structured process for containing, investigating, and recovering from AI security events when preventive controls fail.