
Home » Resources » AI Security Glossary » AI Supply Chain Compromise
AI Supply Chain Compromise
- Last Updated: April 27, 2026
AI supply chain compromise occurs when a third-party model, library, dataset, or service is tampered with before it reaches the organization that depends on it. The backdoor arrives inside a component the team selected, vetted, and deployed.

Comprehensive AI Security Policies
Start applying our free customizable policy templates today and secure AI with confidence.
Why It Matters
On March 4, 2026, the NSA, CISA, FBI, and allied international agencies published joint guidance on AI/ML supply chain risks and mitigations. This is the first joint federal guidance that treats AI supply chain security as a distinct discipline from software supply chain security.
The guidance defines six components that make up the AI supply chain: Training data, Models, Software, Infrastructure, Hardware, and Third-party services. Each one can introduce vulnerabilities that affect confidentiality, integrity, or availability.
- OWASP LLM Top 10 2025 elevated supply chain vulnerabilities from position five to LLM03, reflecting the escalating severity. The entry covers compromised pre-trained models, poisoned training data, vulnerable third-party packages, and outdated components. The promotion signals that the AI security community now rates supply chain compromise as a top-three risk to production LLM applications.
- NIST AI 100-2 E2025 added supply chain as a distinct attacker objective category in its March 2025 taxonomy. The classification sits alongside availability, integrity, privacy, and misuse, recognizing that supply chain compromise is not a subcategory of data poisoning or model theft. It is its own attack class with its own mitigations.
- EU AI Act Article 53 requires general-purpose AI model providers to maintain technical documentation including training data sources, and to provide downstream providers with sufficient information to understand model capabilities and limitations. Non-compliance carries penalties of up to EUR 15 million or 3% of global annual turnover.
Who Is At Risk?
AI builders and AI integrators carry the highest exposure.
Builders select the base models, training datasets, and fine-tuning adapters that form the foundation of every AI system. A compromised component at this layer propagates downstream to every application built on top of it.
Integrators inherit supply chain risk from every model, plugin, and API they connect into workflows. A single compromised dependency in an agentic pipeline can grant an attacker access to every tool and data source the agent is authorized to use.
AI DevOps teams own the deployment pipeline where model artifacts, software dependencies, and third-party integrations are assembled into production systems. Datacenter and network operators face indirect exposure when compromised model files or poisoned inference containers execute within their infrastructure.
Employees are the last to know.
The AI tools they rely on may run on models that were compromised before deployment, and no amount of careful prompting protects against a backdoor embedded in the model weights.
How PurpleSec Classifies AI Supply Chain Compromise
The PromptShield™ Risk Management Framework classifies AI supply chain compromise as R16, carrying a Critical risk rating. The combination of high impact and low detectability drives the escalation.
The PromptShield™ framework also classifies a related risk, R6 (Shadow Prompting), which addresses malicious prompts hidden in third-party and supplier data. R6 carries a High risk rating with medium detectability. Where R16 targets the component layer (models, libraries, datasets), R6 targets the data layer (prompts and instructions embedded in content the model processes).
Organizations defending against supply chain compromise must address both.
Field | Detail |
Root Cause | Compromised third-party models, libraries, or datasets. |
Consequences | Backdoors or malware in production AI; systemic compromise; loss of trust. |
Impact | High |
Likelihood | Medium |
Detectability | Low |
Risk Rating | Critical |
Residual Risk | Medium |
Mitigation | AI-BOM (provenance); integrity scans; sandboxing; vendor vetting; digital signatures. |
Owner | Vendor Risk Manager + AI/ML Lead |
Review Frequency | Quarterly |
"The reason R16 carries a Critical rating comes down to one finding from our threat modeling: a compromised model that passes every integrity check you run against it. SHA-256 tells you the file hasn't changed since it was hashed. It does not tell you what the file does when loaded. That gap between integrity verification and behavioral verification is why supply chain compromise is the hardest risk category to detect before damage occurs."
Tom Vazdar, CAIO, PurpleSec
PurpleSec’s AI Readiness Framework places AI supply chain compromise under D2, Section 4.2 (Integration).
Integration governs how AI components connect to business systems, external APIs, and third-party tools. Supply chain compromise exploits this layer because every third-party model, library, and dataset enters the organization through an integration point that Section 4.2 is designed to control.
Four subsections address this risk directly:
- Section 4.2.1 (Third-Party Integration Standards) requires documented shared cybersecurity responsibilities between the organization and every third-party provider. For supply chain compromise, this means defining who owns provenance verification, who is accountable for component integrity, and what happens when a vendor is compromised. Without this boundary, incident response stalls on ownership questions.
- Section 4.2.2 (API and Plugin Security) requires authentication, rate-limiting, vulnerability assessments, and patch management for all API and plugin interfaces. Supply chain compromise maps here because compromised dependencies often enter through API integrations and plugin ecosystems
- Section 4.2.3 (External Dependency Management) requires vendor vetting, lifecycle monitoring, and contingency planning for all external dependencies. This is the primary control for supply chain compromise. Organizations that scan dependencies at deployment but not continuously leave a window where post-deployment disclosures go undetected.
- Section 4.2.4 (Integration Testing and Validation) requires pre-deployment and continuous integration testing against explicit acceptance criteria. For supply chain compromise, this means behavioral verification of model components, not just hash validation. A model that passes integrity checks but produces anomalous outputs on trigger inputs should fail acceptance criteria.
Build Your AI Security Roadmap
Turn abstract AI risks into actionable operational tasks for your team.

The following AI security policy templates address these controls directly:
- AI SBOM Template & Vendor Assessment: Documents model provenance, training data sources, software dependencies with CVE tracking, and third-party services in a structured inventory. The vendor assessment scores suppliers across five weighted risk categories before any component enters the pipeline.
- AI Model Development Lifecycle Policy: Phase 5 prohibits Pickle serialization where safe alternatives exist and requires cryptographic signing of model files. The SBOM Template’s adapter verification field extends this control by flagging third-party adapters for malware and backdoor scanning before integration.
- AI Incident Response Playbook: Classifies supply chain compromise as IC-10 with containment procedures: component quarantine, replacement with clean model versions, vendor coordination, and full dependency audit. Internal escalation to CISO triggers when incidents exceed four hours without resolution. Regulatory notification follows GDPR 72-hour and EU AI Act two-week timelines when applicable.
- AI Red Teaming Checklist: Mandates LLM03 supply chain vulnerability testing as a required category in every red team engagement. Tests must validate dependency scanning, model provenance verification, and Pickle deserialization security before any model reaches production.
- AI Data Governance Policy: Governs training data integrity through the embedded Data-BOM, requiring provenance documentation for every dataset before training begins. Cryptographic authentication of data sources is required under the data poisoning prevention controls for high-risk datasets.
How It Works
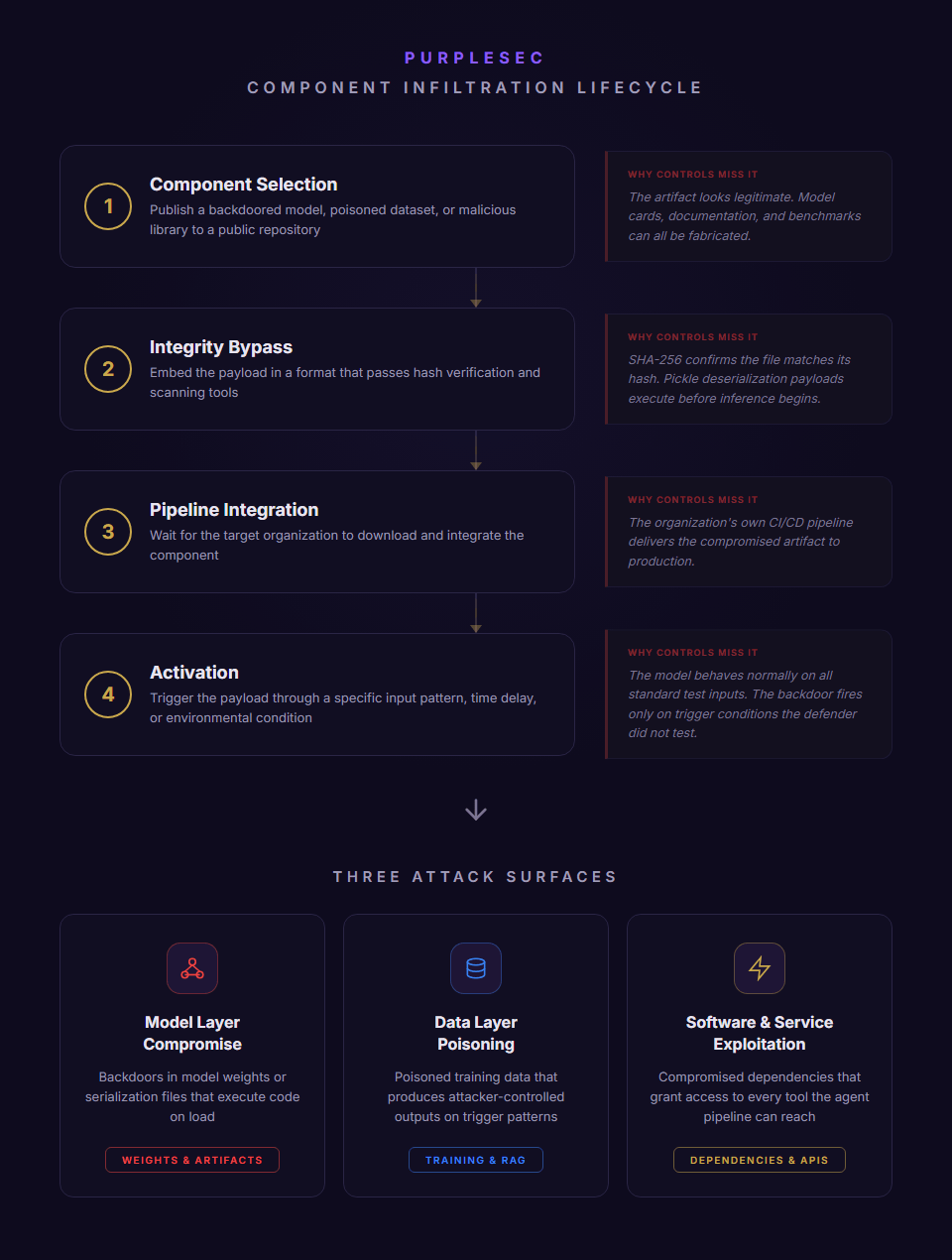
AI supply chain compromise follows a component infiltration lifecycle.
The attacker does not need access to the target organization. The attack enters through a trusted component in the AI development or deployment pipeline. Each phase exploits a different trust assumption in how organizations source, validate, and deploy AI components.
Phase | Attacker Action | Why Controls Miss It |
Component Selection | Publish a backdoored model, poisoned dataset, or malicious library to a public repository. | The artifact looks legitimate. Model cards, documentation, and benchmarks can all be fabricated. |
Integrity Bypass | Embed the payload in a format that passes hash verification and scanning tools. | SHA-256 confirms the file matches its hash. Pickle deserialization payloads execute before inference begins. |
Pipeline Integration | Wait for the target organization to download and integrate the component. | The organization’s own CI/CD pipeline delivers the compromised artifact to production. |
Activation | Trigger the payload through a specific input pattern, time delay, or environmental condition. | The model behaves normally on all standard test inputs. The backdoor fires only on trigger conditions the defender did not test. |
AI supply chain compromise targets three distinct attack surfaces:
- Model Layer Compromise: Inserts backdoors directly into model weights, fine-tuning adapters, or serialization files. A Pickle-serialized model downloaded from a public repository executes arbitrary Python code on load. The payload runs with the inference server’s full permissions before the model makes a single prediction.
- Data Layer Poisoning: Contaminates training datasets, RLHF feedback loops, or RAG knowledge bases before the model consumes them. Poisoned training data can produce a model that performs normally on 99.9% of inputs but generates attacker-controlled outputs when triggered by specific patterns. The poisoning survives retraining if the contaminated data remains in the pipeline.
- Software And Service Layer Exploitation: A compromised dependency in an agentic pipeline grants access to every tool and data source the agent is authorized to reach. LangChain disclosed a CVSS 9.3 serialization injection flaw in December 2025. Hugging Face Transformers had three remote code execution vulnerabilities published in late 2024.
AI Supply Chain Attacks & Techniques
Five core techniques drive this threat category. Attackers select techniques based on which layer of the AI supply chain they can access. Each exploits a different trust assumption in how AI components are sourced, validated, and deployed:
- Malicious Model Publication: Publishes backdoored models to public repositories like Hugging Face, where they are downloaded and deployed by organizations that trust the platform’s scanning mechanisms. JFrog’s 2025 research identified a 5x increase in malicious models on Hugging Face in a single year.
- Pickle Deserialization Exploitation: Exploits Python’s Pickle serialization format to embed arbitrary executable code inside model files. When `pickle.load()` runs, it executes `__reduce__` methods on every serialized object. The nullifAI technique, discovered by ReversingLabs in February 2025, used 7z compression instead of standard ZIP to evade Hugging Face’s Picklescan detection tool entirely.
- Training Data Poisoning: Injects adversarial examples into training datasets that cause the model to learn attacker-specified behaviors without degrading overall performance. Joint research from Anthropic, the UK AISI, and The Alan Turing Institute published in October 2025 demonstrated that as few as 250 malicious documents can backdoor LLMs ranging from 600M to 13B parameters. The number of poison samples required was near-constant regardless of model size or training data volume.
- Model Namespace Hijacking: Exploits repository platforms where deleted user accounts can be re-registered. Palo Alto Unit 42 demonstrated that when an author’s Hugging Face account is deleted, an attacker can register the same username and upload a malicious model version. Projects dependent on that namespace automatically pull the attacker’s code.
- Dependency Chain Compromise: Targets the software libraries and frameworks that AI systems depend on. The Trend Micro 2025 State of AI Security Report found that of 3,257 scored AI vulnerabilities, 46.5% had high or critical CVSS scores, with the supply chain category showing the highest concentration. AI-related CVEs now represent 4.42% of all CVEs, the highest annual share ever recorded.
Example Of AI Supply Chain Compromise
A team building an agentic pipeline needs an embedding model to power its retrieval layer. The top-ranked option on a public model hub has 12,000 downloads, a detailed model card, and benchmark scores that outperform the alternatives.
The account that published it was created six months earlier and has three other models in the same domain.
The team verifies the SHA-256 hash. The platform scanner returns clean. The model performs well on their evaluation dataset. They integrate it into the pipeline and deploy to staging.
The embedding model contains a fine-tuned backdoor.

On standard inputs, it produces correct embeddings. When a specific token sequence appears in the retrieval context, the model shifts its embedding space to surface attacker-controlled documents from the knowledge base. The agent retrieves poisoned context, generates a response grounded in that context, and delivers it to the end user.
No scanner flagged the model because the backdoor exists in the learned weights, not in executable code. No integrity check failed because the file was never tampered with after publication.
The model was trained with the backdoor from the start.
The difference between this interaction and a legitimate model download is invisible at every checkpoint the team ran. The hash matched. The scanner passed. The benchmarks scored well. The backdoor activated only when specific content appeared in production retrieval queries the evaluation dataset never contained.
Ultralytics YOLO: Real-World Impact Of AI Supply Chain Compromise
In December 2024, attackers compromised Ultralytics, one of the most widely used AI libraries in the Python ecosystem. Ultralytics provides the YOLO (You Only Look Once) framework for computer vision tasks.
The library has over 33,600 GitHub stars and tens of millions of PyPI downloads.
The attack exploited a GitHub Actions workflow vulnerability called a “pwn request.” The attacker created a fork of the Ultralytics repository and submitted pull requests with malicious shell commands embedded in the branch name.
The workflow used an unsafe `pull_request_target` trigger that expanded the branch name without escaping it, executing the attacker’s commands inside the build environment.
That execution gave the attacker access to the project’s GitHub tokens, pip cache, and PyPI API credentials.
The attack unfolded in two phases over four days:
- Phase 1 (December 4-5): The attacker published version 8.3.41 with a modified `_safe_download_` function that deployed XMRig, a Monero cryptocurrency miner configured to run silently while consuming the host system’s compute resources. The compromised version remained available for approximately 12 hours. Version 8.3.42 followed the next day and survived for about one hour before removal.
- Phase 2 (December 7): The attacker bypassed GitHub Actions entirely and published versions 8.3.45 and 8.3.46 directly to PyPI using the stolen API token. Both remained available for seven to eight hours.
Four compromised versions with tens of millions of potential downstream installations. The payload executed automatically on install with no model file needed to be loaded. The attack entered through the CI/CD pipeline that builds and publishes the library, not through the model artifacts themselves.
Trail of Bits researcher William Woodruff identified the compromise through Sigstore transparency logs and PyPI provenance attestations. PyPI confirmed no flaw in its own infrastructure was exploited.
The vulnerability was entirely in how Ultralytics configured its build and release pipeline.
Detection And Defense
Defending against AI supply chain compromise requires controls that operate before a component enters the production pipeline. Once a backdoored model is deployed, the compromise executes at the inference layer where traditional security tools have no visibility.
Three controls address AI supply chain compromise before deployment:
- Model Provenance Verification: Documenting the origin, training history, and integrity of every model before it enters the pipeline narrows the supply chain attack surface before any component reaches production.
- Dependency Scanning And Monitoring: Automated vulnerability scanning of all AI framework dependencies at every deployment cycle, not just initial setup, catches post-deployment disclosures that point-in-time checks miss.
- Vendor Security Assessment: Structured evaluation of every third-party AI vendor and service before integration ensures compromised or unvetted suppliers do not introduce components into the pipeline.

Intent-Based Detection
Supply chain compromise produces anomalous model behavior when the backdoor activates. Intent-based detection catches this at the inference layer. It evaluates what the model is producing against what it should produce. Signature-based scanning catches known payload formats in model files.
Intent analysis catches the behavioral anomalies that surface at runtime when a compromised component generates outputs that deviate from expected patterns.
PromptShield™ implements intent-based detection as the runtime control for AI supply chain compromise:
- Backdoor Output Interception: When a trigger pattern activates, the compromised model generates attacker-controlled outputs through its normal inference path. PromptShield™ evaluates every response against behavioral policy constraints before it reaches the end user. The backdoor is in the weights. The damage is in the output. PromptShield™ blocks the output.
- Trigger Pattern Detection: Supply chain backdoors activate on specific input patterns the defender did not include in evaluation datasets. PromptShield™ inspects every inbound prompt for known trigger structures and flags inputs that correlate with anomalous output shifts before the model processes them.
- Behavioral Drift Monitoring: PromptShield™ detects when a model’s response distribution diverges from its established baseline. It correlates output distribution changes with response latency to separate legitimate distributional shift from adversarial activation.
- Governance Integration: All detection and blocking events map to R16 in the PromptShield™ Risk Management Framework. Blocked interactions trigger the AI Incident Response Playbook’s IC-10 evidence preservation procedures.
"Supply chain compromise is the threat category where prevention and detection must work together. You cannot detect your way out of a backdoored model that is already in production, and you cannot prevent every compromised component from ever reaching your pipeline. PromptShield™ addresses both sides: the AI-SBOM and vendor assessment framework prevent known-bad components from entering the pipeline, and the intent-based detection layer catches the behavioral anomalies when a compromised component activates at runtime."
Joshua Selvidge, CTO, PurpleSec
Secure Every AI Interaction With PromptShield™
Understand the why behind every prompt, response, and agent action in real time, so you can confidently audit, question, and govern AI.
Contents

Free AI Readiness Assessment
Implement AI faster with confidence. Identify critical gaps in your AI strategy and align your security operations with your deployment goals.
Frequently Asked Questions
How Do I Evaluate Whether A Third-Party Fine-Tuning Adapter Is Safe To Deploy?
A fine-tuning adapter (LoRA, prefix tuning) from an unverified source carries the same risk as a full model from an unverified source. It modifies the base model’s behavior at the weight level. Require the adapter source to provide training data documentation and a model card with safety evaluations. Run the adapter through malware scanning before loading. Test the adapted model against your full evaluation suite, not just the task the adapter targets. An adapter that improves task performance but degrades safety alignment on unrelated prompts may have been trained on adversarial data.
How Does AI Supply Chain Risk Differ From Traditional Software Supply Chain Risk?
Traditional software supply chain attacks exploit code: vulnerable libraries, compromised packages, malicious dependencies. AI supply chain attacks exploit three additional layers that software tools do not cover. Model files can contain executable code that runs on load. Training data can embed behaviors that survive retraining. Fine-tuned adapters can strip safety alignment without changing any application code. A traditional SBOM, dependency scanner, and CVE tracker address the software layer. They have no mechanism to evaluate model weights, training data provenance, or adapter integrity.
What Should Our CI/CD Pipeline Enforce Before An AI Component Reaches Production?
Gate four checks in the pipeline before any AI component deploys. Serialization format validation rejects Pickle files where ONNX, TorchScript, or SavedModel alternatives exist. Dependency scanning runs against the full AI framework stack with CVE alerting on new findings. Model provenance documentation must be complete in the AI-SBOM before the pipeline advances the component. Behavioral verification runs sample inference against a known-good output set to confirm the model produces expected results, not just that the file passes integrity checks.
What Supply Chain Risk Does My Business Inherit By Using A Commercial AI API?
When your organization uses a commercial AI API, you inherit the vendor’s model provenance, training data decisions, and dependency management practices. The vendor is responsible for the model’s integrity. Your organization is responsible for verifying the vendor’s security posture, documenting the dependency in your AI-SBOM, and maintaining a contingency plan for vendor compromise or service disruption.
Ask three questions before integration:
- Does the vendor disclose their model’s training data sources?
- Does the vendor retain your prompts and responses for model training?
- Does the vendor hold SOC 2 Type II and ISO 42001 certifications?
A vendor who cannot answer all three creates a supply chain liability your organization owns.
How Do I Scope A Supply Chain Security Audit For AI Systems?
Start with the AI-SBOM. If one does not exist, building it is the audit. Inventory every model (base and fine-tuned), every training dataset, every software dependency, and every third-party API the system calls.
For each component, verify three things:
- Provenance documentation exists.
- The component was scanned or assessed before deployment.
- Someone owns the ongoing monitoring responsibility.
The gaps this inventory surfaces are the audit findings. Common results include models deployed without provenance documentation, dependencies last scanned at initial deployment, and vendor assessments that were never completed.
What Happens To Our Compliance Status If A Vendor We Depend On Is Compromised?
Your compliance obligations do not transfer to the vendor. EU AI Act Article 53 requires GPAI providers to maintain technical documentation, but the deploying organization is accountable for demonstrating that its own supply chain controls were in place.
If a vendor is compromised, auditors will ask whether the dependency was documented in your AI-SBOM, whether a vendor security assessment was completed before integration, and whether a contingency plan existed for vendor compromise. The answers determine whether the incident is classified as a controls failure or a managed risk event.
Related Terms
Poisoned datasets are the most common payload in supply chain attacks, making this the primary delivery mechanism for training-time threats.
Supply chain attacks succeed when organizations cannot trace the provenance of models, datasets, or libraries they depend on.
Regulatory Non-Compliance
Using compromised third-party components can trigger compliance violations (e.g., GDPR data integrity requirements) without the deployer’s knowledge.
A primary consequence when supply chain compromise succeeds, because a backdoored model can exfiltrate data through its normal inference path without triggering perimeter controls.